Hi @nicolas.spencer
That’s great that you got the feed working!
As with most things, for your next problem, you have several choices 
You mentioned bash so I assume the worker is running the Linux tentacle. If this is the case, and you have or can install PowerShell Core, then you could choose to use the community step template called SQL - Execute SQL Script Files.
I recently updated the step template to support better file matching when executing scripts from a referenced package.
The idea is that you select your package (continuous-improvement:db-scripts) in your deployment process as usual, and then you select the path to the scripts you want to run using the SQL Scripts parameter. This parameter is multi-line, and you can add one path for each unique file path. If they are all in one folder, you can use a wildcard. Here is a quick example I used to test the template:
The package I chose has this file structure:
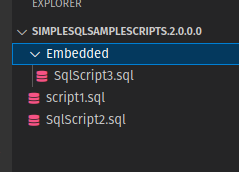
You can see in the task log below the output from the file matching:
You may also notice warnings for paths it couldn’t find, too - I tested the logic to make sure it did highlight paths that weren’t present too.
The scripts will execute using the Invoke-SqlCmd SQL PowerShell cmdlet.
Another thing to note is that I used SQL authentication, and I’d recommend using this authentication method with this step. Others are supported but may not work on Linux.
Using this approach means the connection to SQL, extraction of the package, and selection of files within the script are all handled for you.
If you can’t use the community step template and you need to write the process from scratch in bash, then you can still take the idea from it and use a custom step template, and then you can pass parameters from your deployment process into the step itself. The community step template uses the package parameter type - this allows any consumer of the step to choose the package to be referenced in the deployment process or runbook and not hard-coded in the step itself.
You can also create a copy of the step template from the community library and import it as a custom step in your Octopus instance, and customize it to any other requirements you have (you mentioned above in step 4 needing to run other logic based on the results of the scripts being executed)
Hopefully, that all makes sense, but if not, just let me know, and I’d be happy to answer any further questions!
Best,














